經歷昨天對神經網路跟深度學習的講解,不知道大家還好嗎?今天要順著上一篇的內容來講講深度學習可以怎麼應用在NLP上面。
當初在介紹詞袋模型的時候,我們提到過,雖然詞袋模型是一個把文字轉變成向量的好方法,但是one-hot encoding會讓資料產生太多沒用的0,容易造成維度詛咒。而且詞袋模型完全不會考慮到詞的順序性,沒辦法表現出自然語言的特色。今天就來介紹怎麼運用深度神經網路改善這兩個問題。
word2vec模型發想自J.R. Firth 的 “You shall know a word by the company it keeps.”。大家應該都知道,當我們在學習英文的時候,光是知道一個詞彙在中文裡面對應的意思是不夠的,我們還需要知道他通常會搭配哪些詞彙一起出現還有他是用在什麼樣的文法環境之下才能正確地使用那個詞彙。而word2vec基本上就是在努力讓這件事情可以表現在模型裡面。他假設不同詞彙之間有親疏關係,而這樣的親疏關係可以透過詞彙的上下文表現出來。舉例來說,「漢堡」和「薯條」可能都會比較常跟「速食」和「麥當勞」一起出現,但「陽春麵」不會,所以畫出來的向量跟他們的距離就會比較遠。把向量想像成點的話就會是下面這個樣子: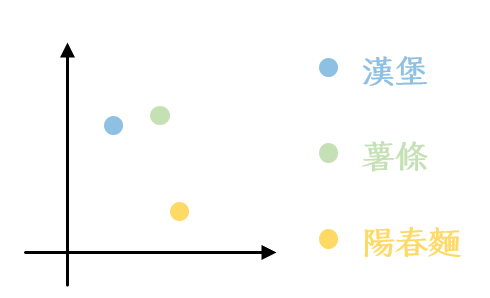
在這樣的假設之下運作的word2vec模型主要有兩種類型,下面會分別介紹他們。
skip-gram的運作主要是透過選定一個目標詞彙跟指定的window size來定義上下文的範圍。接著把目標詞彙的上下文送進去模型訓練再讓模型預測目標詞彙的上下文。以 “I like to learn things about linguistics.” 這句話跟window size為2舉例,我們會取出下面這些資料:
有了這些資料,我們就可以開始訓練模型。但是我們當然不能直接把這些資料放進去,因為電腦根本認不得字。因此,我們一樣需要透過one-hot encoding來把文字轉換成向量的形式。這邊的做法基本上跟BOW沒什麼區別。總之經過這一堆前處理之後終於可以把資料放到input layer裡面。接下來在hidden layer裡面就要體現word2vec模型的厲害(?)之處了。為了把one-hot encoding製造出來的那些多餘的0拿掉,我們要指定一些feature給hidden layer,這些feature就像加權值一樣,會形成我們指定的feature數量跟樣本的維度數量相乘的矩陣。透過input向量跟hidden layer矩陣的相乘就可以達到降維的效果。以總共5個type的語料跟3個指定feature為例,我們會得到下面的結果: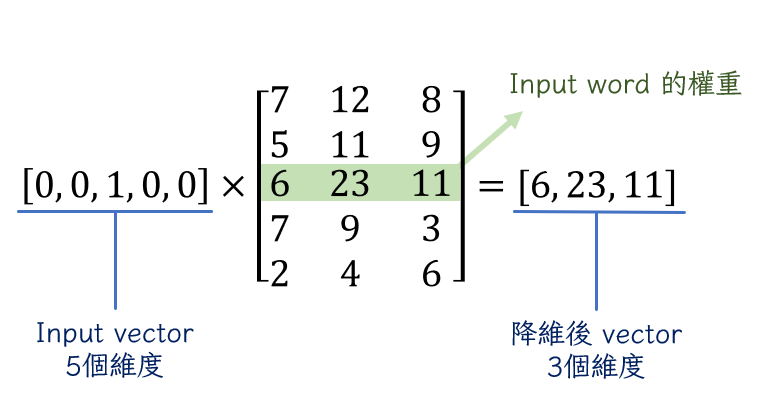
因為input vector除了那個詞本身是1之外,其他都是0,這些0會把hidden layer矩陣裡除了跟這個詞的位置相對應行數的數字都抵銷掉。因此我們可以把這行數字視為模型給予input的權重。可能有人想問hidden layer的數字是怎麼來的,其實就跟最簡單的神經網路模型一樣,是隨機安排再透過不斷更新學來的。雖然從上面例子的5個維度變到3個維度看起來可能沒什麼差別,但如果套用到實際的模型訓練情況,10000個type的語料跟300個feature就可以把10000個維度的向量變成300個維度的向量還把0都去掉了,絕對是很有效的方法。
降維之後,我們要把資料送進下一個hidden layer裡面(沒錯,word2vec是一個雙層神經網路模型),計算目標詞彙跟上下文同時出現的機率,也就是P(context|input word)。因為會跟每一個都計算,所以相乘之後,接續上面的例子,就會輸出一個300×10000的output layer。最後一樣為了把結果轉換成容易理解的機率數字,我們會利用softmax regression來達到目標。
統整一下上面的這些步驟,可以簡化成下面這張圖(出處):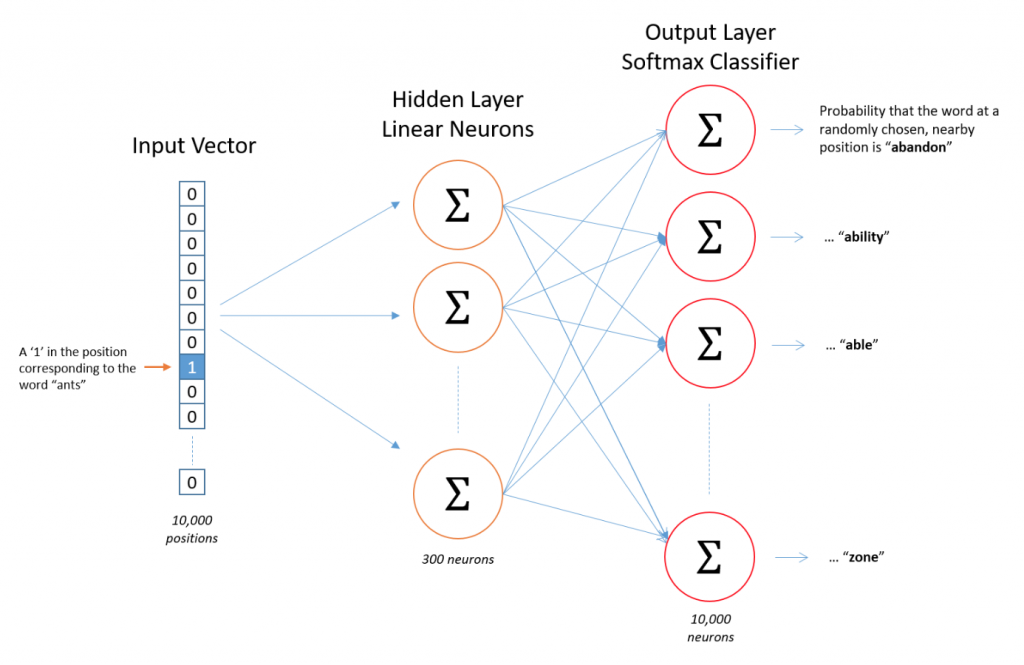
CBOW跟skip-gram的進行方式剛好相反,他是以上下文詞彙的輸入來預測目標詞彙。所以在我們決定上下文要用什麼之後,會先把他們的向量相加再輸入iuput layer。後面做的事情基本上就跟skip-gram差不多,所以這邊就不多做說明,如果對細節有興趣的話,可以參考下面第四篇文章。
今天對word2vec的介紹就到這邊告一個段落,有任何問題都歡迎下面留言回應。下一篇會繼續針對深度學習怎麼應用在NLP領域做介紹,明天見!

